Sometimes it’s obvious what code has to change, but it’s painfully hard to prove you’ve fixed it.
When’s the last time a conceptually simple fix took you hours longer to than planned, because you could not get the project running locally to verify your change worked?
I just want to change a little CSS on the signup workflow… Should be quick! So, starting up the website… just to double check.
$ npm run-script dev-server
Starting Website
[ERROR]
I know what to do. I’ll read the README, follow it step-by-step, and that should solve things.
(Reads README, follows all steps religiously.)
$ npm run-script dev-server
Starting Website
[ERROR]
Ah, I’m just missing an undocumented environment variable. I know this problem… I’ll even update the README afterward to help others.
$ export DATABASE_URL=etc
$ npm run-script dev-server
Starting Website
Database connection established.
[ERROR]
Well, that helped! Sort of. There must be something else missing. I’ll go ask my co-worker whom I saw running the site.
(After debugging for 20 minutes…)
$ npm run-script dev-server
Starting Website
Database connection established.
Website online!
Sweet! I’m all set.
(5 minutes later…)
Everything seems to be running, but some requests are failing locally that would never fail in production. What gives?
On a bad day, getting a complex service running locally can feel like this.
By the time you get it running, you’ve nearly forgotten the simple fix you intended to make.
To fully run one particularly complex Clever service locally requires setting paths to multiple internal and external APIs, a datastore, and a running background job queue.
Did we dig ourselves into a hole? How did we get here? Could we do better?
Problems
Problem #1: Changes to the required environment for an application can surprise developers and cause headaches.
We use environment variables to configure an application on launching it.
Missing environment variables could cause anything from automated test failures to subtle runtime errors.
Even if you document all environment variables required to run an app, there’s always the risk of this falling out of date.
On top of that, as the list of environment variables to set grows, the process of spinning something up locally becomes harder and harder.
Problem #2: Service-oriented architecture is complex to spin up locally.
When working on an application, you need to know all of the services it depends on.
These services need to be downloaded, up-to-date, and running with the correct configuration.
Again, documenting this dependency tree is a sufficient solution, but falls flat in practice as documentation falls out of date and the list of services to manually launch grows.
Problem #3: Services can run in different modes pointing at different, potentially remote services.
Environment variables encode the mode of operation that a service in running in.
For example, sometimes you’d like to point to a local instance of a service, but other times you might want to point to an instance of that service running in a remote staging or test environment.
Encoding these different modes of operation presents an additional challenge that is hard to surmount with documentation alone.
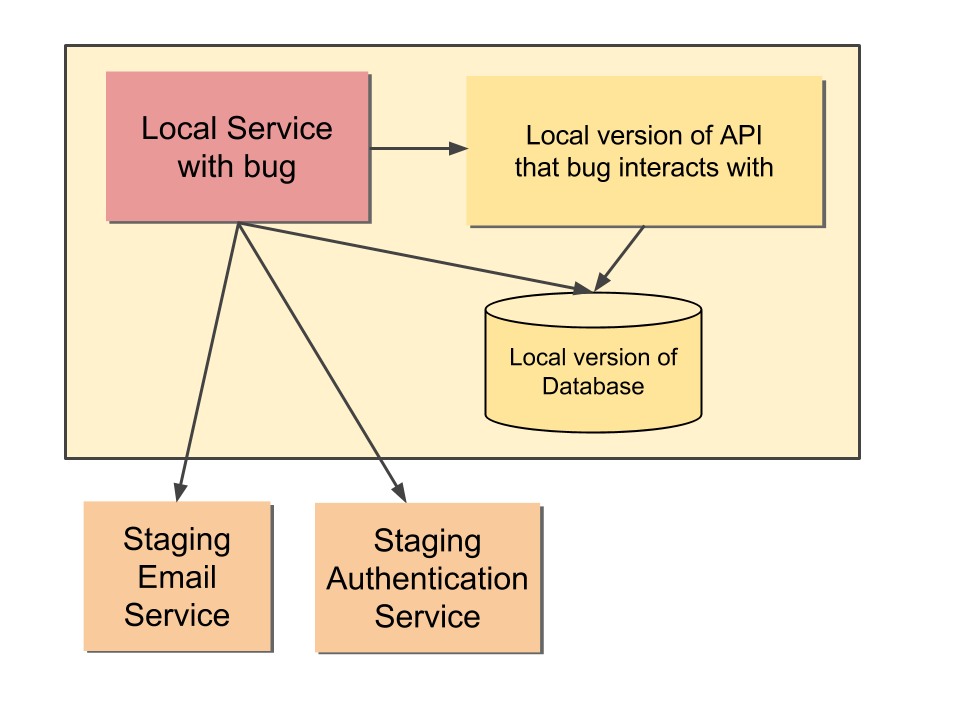
As an example, we might be trying to fix a bug in a service that interacts with an API we also want to modify.
Perhaps we also want to have some sort of account (maybe the account of the person who reported the bug!) that both the API and our service have access to.
However, there are other services like Mandrill or an authentication service that you can’t or don’t want to run locally.
This is painful to set up, and quite complicated as we can see below:
Solutions
Solution part 1: Write a per-service configuration file.
For each service we need to know
- what environment variables the service needs
- the command to launch the service
- what it exposes to other services.
Instead of documenting this in a README, we can encode this in a configuration file that can be read by both humans and programs.
Let’s think of a hypothetical “pong” server that exposes a port to potential “ping” clients:
pong:
setups:
default:
cmd: ./server.sh
publish:
server: "localhost:8080"
Our hypothetical pong service requires no environment variables set, is launched via shell script, and exposes itself on an address that we will name server.
We can specify different modes of operation via setups, but here there is only one setup named default.
Let’s create a ping service that communicates with this server:
ping:
setups:
default:
cmd: ./client.sh
requires:
SERVER: pong.server
The ping service is launched via a shell script and requires a SERVER environment variable.
The SERVER environment variable is provided by the pong service and the server value it publishes.
Solution part 2: Create a tool to automate launching a service and all of its dependencies.
The configuration above tells us everything we need to know to configure and run these services manually.
To automate this process, we’ve created a tool called aviator.
Launching a service is as simple as aviator <name of service>.
Aviator will take care of traversing the dependency tree of the service and launching any dependencies that it finds.
Say we were testing changes to our ping service above. If we tell Aviator to launch ping it will take care of spinning up pong first:
$ aviator ping
-> pong
-> ping
[pong] pong: starting server
[ping] ping: server at localhost:8080 responded 200
Solution part 3: Allow the configuration to specify different modes of operation, and give users the ability to switch between them.
Let’s imagine that instead of ping communicating with a pong server running locally, you instead want to communicate with a “staging” pong server.
The chain of dependencies is the same: ping requires pong.server. However, it’s a different instance of the server.
Aviator supports this by allowing multiple setups for each service. In this case we’ll add a “staging” setup.
pong:
setups:
default:
cmd: ./server.sh
publish:
server: "localhost:8080"
# ----- NEW -----
staging:
publish:
server: “staging-pong-server.example.com”
The staging setup doesn’t have a command (cmd), so if it’s selected, it won’t run any code locally.
Instead, it simply states that pong.server should refer to a different address.
(This assumes that a valid pong server is accessible at staging-pong-server.example.com.)
Now that we’ve updated the pong config to have two setups, let’s run ping again.
Aviator presents the user with a choice of which pong server they would like to use, where default will start a new pong server locally and staging will point to an existing staging server.
$ aviator ping
Configuration options for 'pong':
- default : localhost:8080 "./server.sh"
- staging : staging-pong-server.example.com
Config for pong?
Let’s choose the staging config.
Config for pong?
staging
-> pong
-> ping
[ping] ping: server at staging-pong-server.example.com responded 200
Only ping is run, and it connects to the staging pong server.
With more complex services, this flexibility in choosing configurations can be powerful.
It allows you to modify and debug specific aspects of your service locally while pointing to staging servers for all others.
Aviator + Docker
Clever uses Docker widely to standardize build and deployment.
Aviator is capable of running Dockerized applications.
For example, here’s how you would update the Aviator config to run Pong as a Docker container.
pong:
setups:
# ... other setups: default, staging ...
docker:
cmd: 'docker run -t -p 8080:8080 local/pong-server'
publish:
server: “localhost:8080”
Note that this assumes Docker is running locally, although you could also start the Docker service via an Aviator config and make it a dependency for the docker setup of Pong.
Docker Compose
Docker Compose (formerly known as Fig) is an excellent tool that solves similar problems to Aviator.
Similarities:
- Uses a config file to specify dependencies.
- Launches multiple dependent services.
- Manages environment.
Differences:
- Docker Compose
- Requires all applications be Dockerized
- Allows
psstyle monitoring and restart of individual services - More strictly versioned via Docker image versions
- Aviator
- Works in a heterogenous environment (some Docker containers, some not)
- Allows pointing to staging services (don’t have to run everything locally)
- Less strictly versioned – your local code can be in a bad state or require dependencies to be installed
Aviator has been a flexible tool that has enabled us to develop locally and migrate to Dockerized applications over time. It allows us to choose ourselves what type of deployment – if in the future we decide to move away from Docker, we can use Aviator to help with that as well!
Conclusion
At Clever, we’ve found that Aviator solves many of the pain points that SOA / microservices introduce.
Aviator helps us onboard new devs more quickly, jump into rarely-touched codebases without lengthy setup, and generally keeps us from going insane.
We hope you enjoyed learning more about Aviator, and we hope it will be as useful for you as it is for us!
Check out Aviator on Github and try running the examples.
There is still work to be done, and we’d love help – if you’re interested in contributing to Aviator, do let us know via Github issues.
Thanks for reading and please share your thoughts on Hacker News if you think Aviator is a great/dumb/mind-blowing/world-ending idea.