Why multi-region sessions?
Each year leading up to Back to School (our busiest season), Clever’s engineering team invests in our highest traffic systems to make sure we can handle user growth and new traffic patterns. During 2020–2021, SAML auth at Clever grew from <10% of our login related traffic to about 40% of our traffic! For this reason, we wanted to be sure that it was robust to rare but catastrophic issues like an AWS region outage.
Although the context for doing this work involved sessions and SAML… nothing below is SAML specific, nor is it particularly session specific! These are resiliency patterns.
What is a session?
This diagram shows how a user creates a session:

The user’s browser keeps track of a session ID that identifies them, and the server can use that session ID to look up all other data related to the user’s session.
5 stages of session resilience
With that flow in mind, let’s walk through 5 stages of making this more resilient to failure!
We’ll start with just a user and an application server. What could go wrong?

“So I deployed a new version and all our users just got logged out…”
Keeping your session data only in-memory isn’t a viable real-world solution. If the service restarts for any reason (whether a failure or a normal deploy), all session data will be lost.
First, we’ll add a database to provide persistence of the session data.
Next, to improve our service availability, we’ll run multiple copies of the service. Regardless of which copy of the service the user communicates with, or if one crashes or is redeployed, the session will be available.
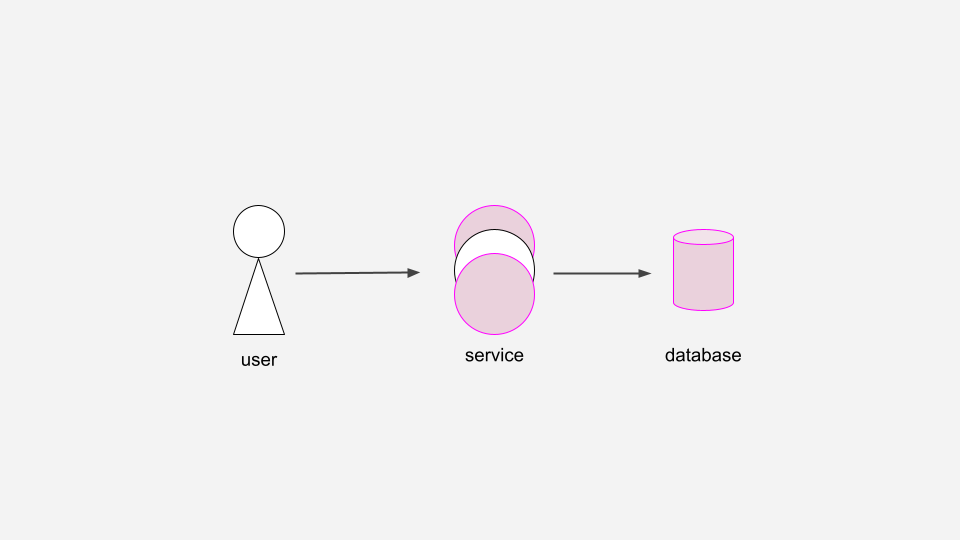
This helps a lot, but we’ve introduced a new single point of failure…
“Uh-oh, the database isn’t responding to requests!”
Perhaps the database was overwhelmed and ran into some resource limit (CPU, memory, connections, etc), or the instance became unavailable due to a networking issue.
To become more robust to a single DB instance failure, we’ll run several database replicas. This allows us to fail over to one of the replicas if the primary DB instance goes down.

Looking quite good! But wait a minute…
“Are you serious… all the copies of the database failed at once?!”
Maybe a cascading failure caused the DBs to fail one by one. Or perhaps a networking issue in the data-center caused your service to be entirely unavailable to the user. Regardless, that’s too bad users won’t get to enjoy your DB replicas.
To handle this case, we’ll mirror the entire setup into another region.
Beyond that, we’ll replicate changes across regions. Some databases provide this feature directly (example: DynamoDB Global Tables) while others would require a custom solution.

Awesome, we’re now more robust to an entire data center failing!
“So… I was just looking at our AWS bill…”
Turns out that it costs a lot of money to synchronize all data among all your databases in all your data centers (example: DynamoDB Global Tables).
This brings us to Clever’s current approach to multi-region sessions. We use DNS with a geolocation routing policy to direct each user to only one data center. For example, someone in New York would always be routed to us-east whereas someone in California would be routed to us-west. This means that under normal circumstances, a single user talks only to one data center, and there’s no need to replicate their session elsewhere.
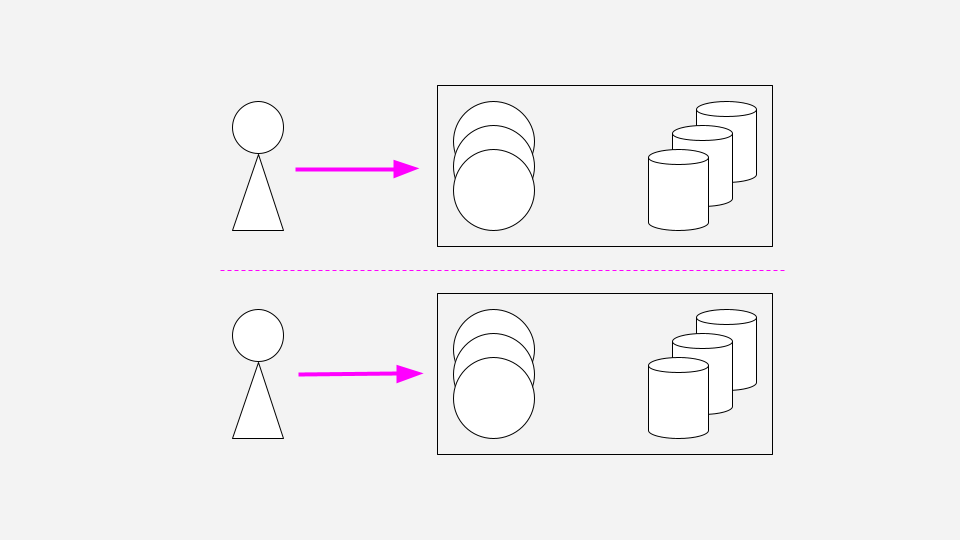
“But seriously, us-west is down!”
What happens to the user in California if the us-west data center fails? The user will lose their session (get logged out); however, we can quickly recover by changing our DNS geolocation routing policy to point such users to us-east. Now the user can login again.
This recovery strategy means we had to build processes to easily and safely update our routing policy. Moreover, we had to be sure the other data center could scale up to handle the additional load.
We decided to trade-off complete availability during a data center failure for a much less expensive solution that still provides a way to recover quickly, should this rare disaster scenario occur.
Closing Thoughts
Our approach highlighted a few things for me:
- Trade-offs. Resilience may cost more money. It also may require a more complex system with new edge cases to consider.
- Reusable solutions. Clever had already used this approach once in another core Single Sign On service. We were confident that it would work and that it could scale well. Beyond that, re-using it makes our systems easier to maintain and debug: the two services import the same library code, and the underlying databases are configured identically other than scale.
Thanks to the folks who implemented this the first time around, and made it so easy for me learn from and reuse this approach. And thank you for reading!
p.s. Does this sound like fun engineering work? Want to work on a product used in over 50% of US schools? Apply to Clever!
One more thing…
Recall the solution we arrived at, where each user’s session is written to a single data center.
What happens if we don’thave an outage, but for some reason a user tries to look up their session in the wrong data center? We call this scenario session flopping.

A possible solution could be to fallback, checking in the other region’s data center first before creating a new session:

This unfortunately means that every database miss requires a fallback request, which is quite expensive. If you have >2 regions, it also has the downside of fanning out!
To avoid unnecessary fallback queries, we encode a user’s region in the session ID when the session is first created. We can use this to intelligently fallback.

For example, if the Session ID has a prefix of “east” but the request arrived at the “central” data center, we will route the request to“east” to lookup their session.
This means we need at most one fallback , because we will only make that request if we’re certain that the session came from another data center.