At Clever we move a lot of data, both from school districts into Clever and from Clever into all the external places that school districts want that data shared. Broadly, we call this behavior “syncing”, and various sync flavors show up across Clever. Let’s talk about two ways to perform data syncs by using an analogy – checking the fridge before your weekly grocery shopping trip.
Diff-based fridge checking
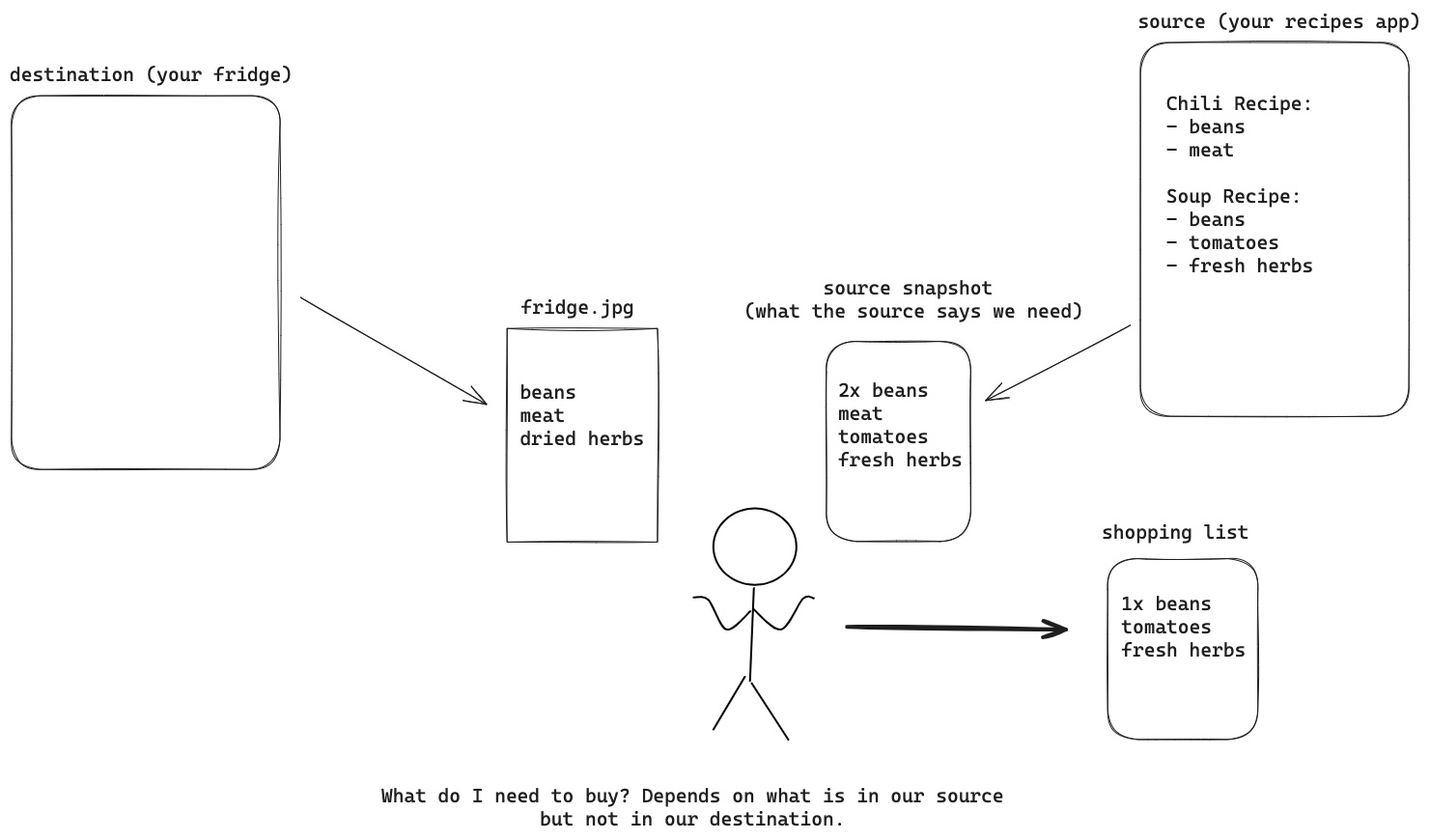
We’ll start with a hypothetical in which you’ve figured out what you want to cook for the week and have come up with a big list of ingredients you need. Now to figure out what you actually need to buy. Let’s say for this example, all your ingredients are stored in the fridge (as opposed to the cupboard or pantry etc etc). To avoid standing in your open fridge slowly checking off a list of ingredients, you take a picture of your fridge instead and compare that against the list of ingredients that you need. Then you simply go and buy any ingredients you don’t have. Easy. There are a couple consequences to this approach.
Snapshots
For this approach you require two “snapshots” – the picture of your fridge and your list of ingredients. In an actual data sync, these would be a snapshot of your source data and a snapshot of your destination, i.e. the place you are writing your data. For very large data sets, these snapshots may get very large, or take a long time to capture. In addition, you’ll need to capture these (potentially large) snapshots whether the actual changes required are small or large. In our analogy, this would be like your fridge having 49 of the 50 ingredients you need for the week – you won’t know you only have to buy 1 ingredient until you look at the whole fridge for all 50 of your ingredients.
On the bright side, snapshots can make debugging easier. If snapshotted data are the only, or at least primary, inputs to your sync, it can be easy to reconstruct a sync and determine why something happened. Also, the fact that snapshots capture the whole destination make it easy to enforce uniqueness, say across an identifier field; the only way to know an identifier is unique is by looking at all the other identifiers in the destination. Having a complete snapshot makes this trivial.
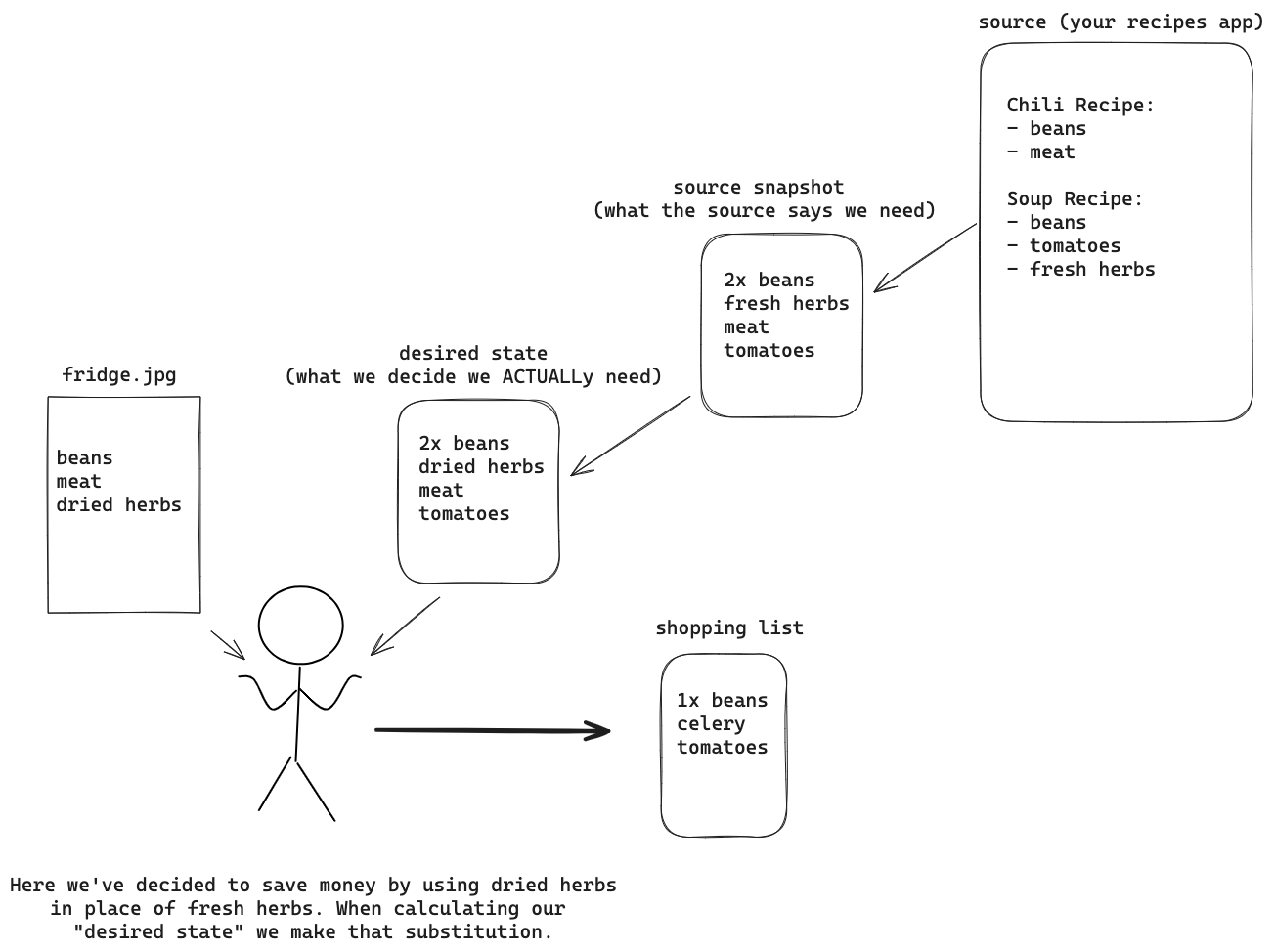
Desired State
Something worth noting here is that in a diff-based sync you have to calculate the desired state of the destination. This is like coming up with the big list of ingredients you need for all your recipes. In the analogy, this offers an opportunity to optimize, for example buying common ingredients in bulk or finding economical substitutions that you already have.
In a real world syncing example there are similar consequences. Maybe you want to sync a value to your destination that is conditional on multiple other values – because you are required to calculate the desired state, it is almost trivial to calculate new values that are not in your source data.
Buggy Syncs
This one is a little more difficult to work into the analogy so I’ll skip straight to the point. Let’s say you deploy some buggy code and one particular value gets synced incorrectly. Being a superstar engineer, you catch the issue quickly and deploy a fix. The cleanup here is super easy – on the next sync, your system will see the incorrect value and fix it, because fixing out-of-sync date is exactly what it’s designed to do. A diff-based sync makes a destination data set self repairing.
This is a great opportunity for customer-facing features to double as bulwarks against internal mistakes. Let’s say you make a feature that automatically stops syncs that try to change more than 20% of a data set at a time. This feature may also work to limit the blast radius of a bad code change that would otherwise cause huge data changes! Of course this isn’t a replacement for thorough testing and well-considered rollouts, but it also doesn’t hurt.
Events-based fridge checking
Let’s consider a different method of grocery shopping. You get an app that plans all your meals out for you. It tells you exactly what to buy based on what it knows you will use up cooking the meals it tells you to cook. In our real world example, this is like an events-based sync where our system listens to some source of events and replicates those changes to the destination 1:1.
You may wonder…who is this magical event emitter? Let’s say your system’s goal was to replicate entries from a DynamoDB table to a MongoDB Atlas cluster. You set up Streams on your DynamoDB table and wam-bam you’ve got an event emitter! The crucial thing here is that the event emitter has taken on the responsibility of deciding what changes need to be made.
What are some of the consequences of an event-driven sync?
No Snapshots
Our system no longer needs a destination snapshot since the scope of our system has been reduced and we no longer need to calculate the desired state of the destination. In our analogy, we simply buy the things the app tells us to, without considering what we have in our fridge. Let’s introduce a diagram:
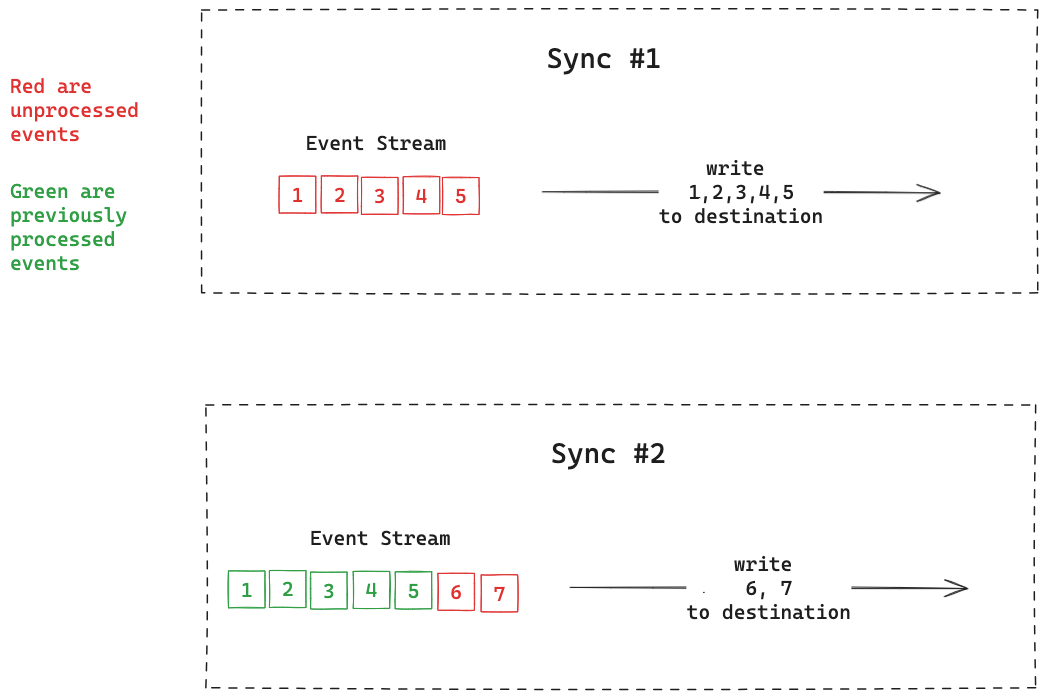
In this diagram we’re showing how your system might handle an event stream. In the first sync, there are 5 events you haven’t processed yet in the stream, so you write those 5 events to the destination. In the second sync, you only have 2 unprocessed events so you write those.
Manual Changes
Imagine our roommate just so happens to buy the cheese that we’re going to need for a recipe. In an events-based sync, the app would have no idea that our fridge has this cheese already and so we would go out and buy a second piece of the same cheese. This could be a good thing if our roommate is particular about us not eating their food, or it could be an issue if they bought the cheese specifically for us!
In a real world scenario, this means an events-based sync can easily preserve manual changes in the destination. Since our sync only makes changes in response to the event source, destination changes will not be overwritten until an event comes along that would overwrite that manual change. This may or may not be desirable behavior depending on what your system is trying to achieve.
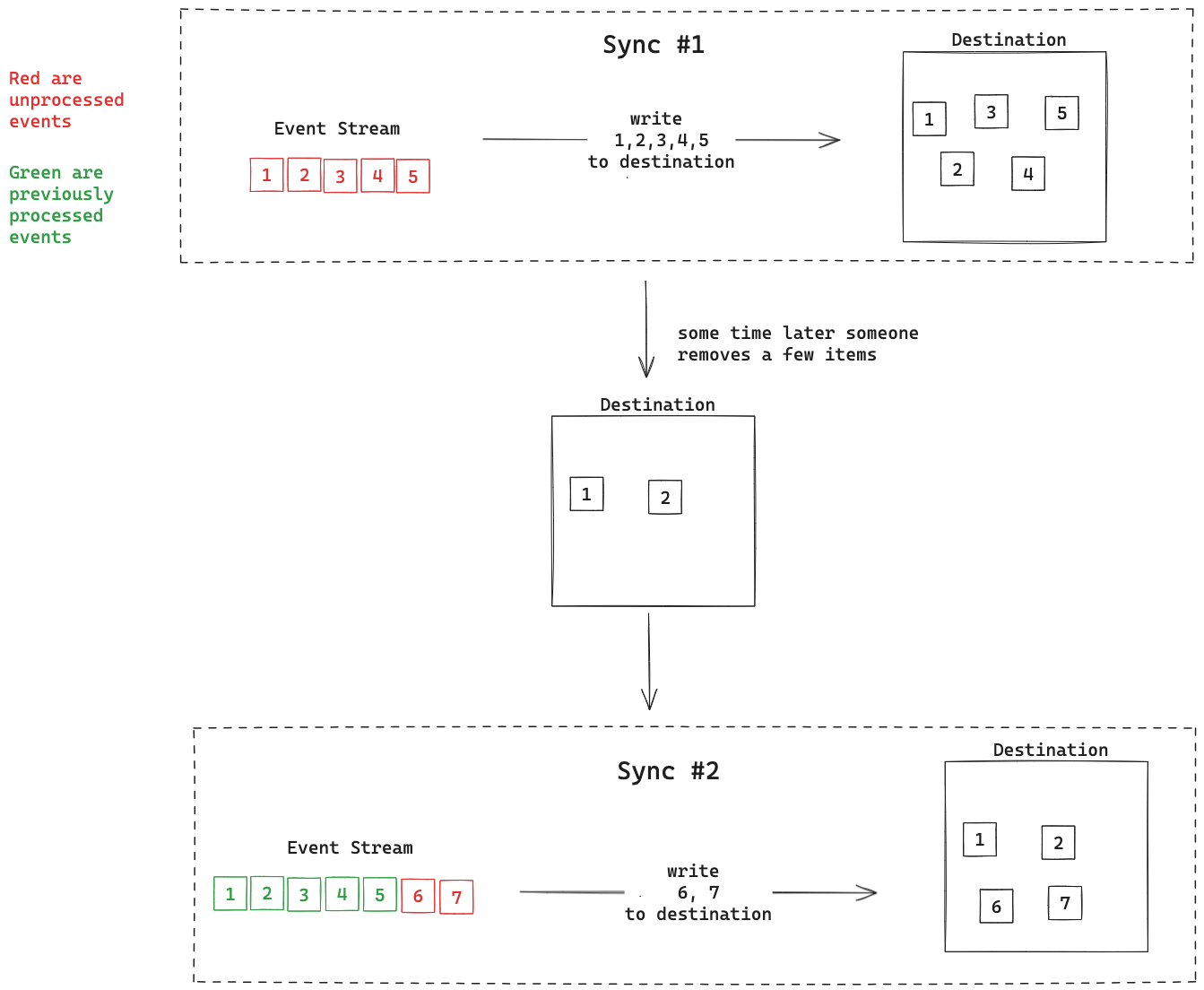
In this diagram we sync items 1 through 5 to the destination. Before our next sync, items 3, 4, and 5 are removed. After sync #2, only items 1, 2, 6, and 7 are in the destination. We’ve preserved the manual removal of items 3, 4, and 5.
Errors
In an events-based sync, errors have to be handled very carefully. What kind of errors are we talking about? These could be transient network errors that persisted through retries, errors as a result of destination misconfiguration, or errors stemming from source data issues. In the first two cases, we need to be careful to “carry forward” errors between syncs – that is, if an operation errors in a sync, we should make sure to retry that operation in the next sync. We need to do this because the source event for the erroring operation will not necessarily be included in the next sync! This error carry-forward logic may be complex, and is a logic flow we don’t need to consider at all in a diff-based sync.
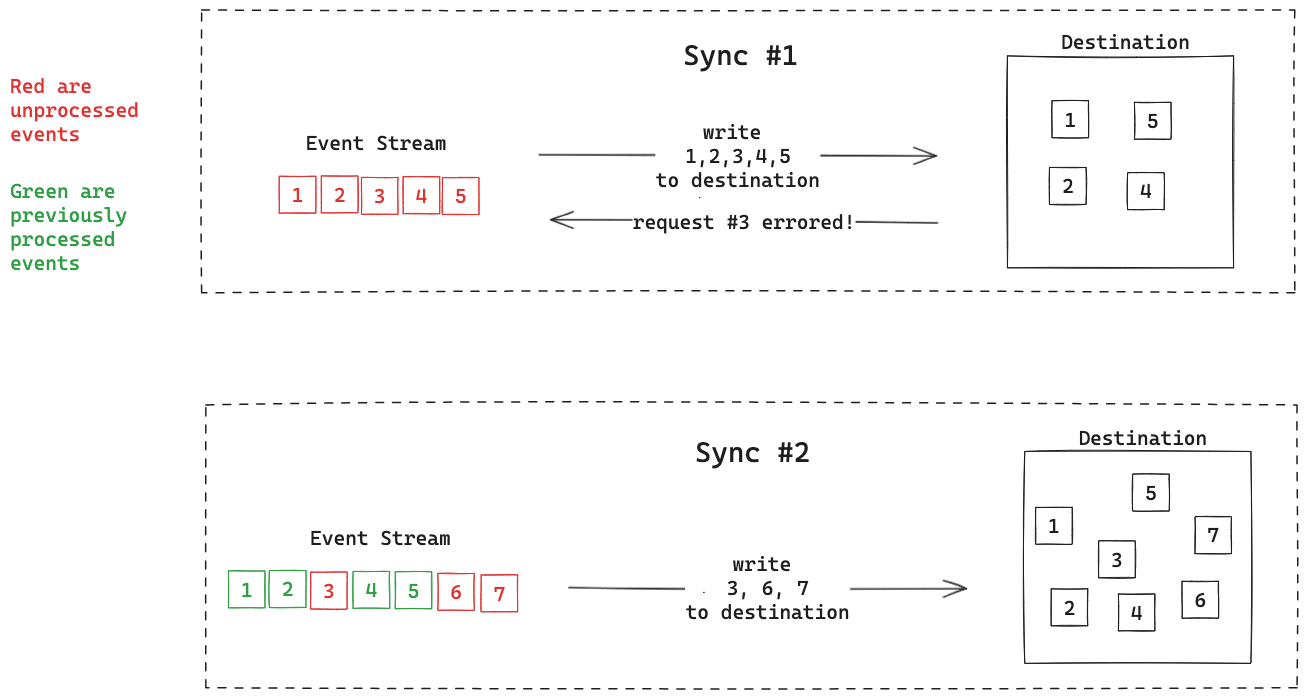
In this example we ran into an error processing event #3. Now if we want to ensure that event 3’s data makes it to the destination, we will need to find a way to remember to retry event 3 in the next sync.
Order of operations
Finally, with an events-based sync you may need to consider the order in which you apply your changes. Using the Event Stream example, if two changes happen to the same document, your sync will need to apply these changes in order or else risk putting that entry in the incorrect state. The most straightforward solution – collapsing multiple events that happen to the same entry into one – works well in this example but may turn out to be difficult with more complex data structures. And if your system applies changes in parallel, perhaps across multiple containers, coordinating event ordering becomes an issue.
Wrapup
We’ve talked a bit about diff-based and event-based syncs and some of the differences between them. There are significant unique features of each that make each more or less applicable in different product scenarios. Do you need to enforce uniqueness? Do you have an event stream available? How do you want to handle manual changes in your destination? These are all questions worth asking before committing to a particular approach.
We’ve also talked a lot about stocking a refrigerator. How do I stock my fridge? I go to the grocery store and yolo sync, just hoping I remember what I’ve got at home.