On Tuesday, Wednesday, and Thursday, March 6th-8th, 2018, Clever logins failed for all customers: 1h on Tuesday, 1h15 on Wednesday, and almost 5h on Thursday. This was Clever’s single worst outage ever in length, repeatedness, and impact. This postmortem is the first of many public steps we’ll be taking to ensure Clever is a service you can fully rely on. We’ll explain the sequence of events, the root causes we identified, and what we’re doing to improve Clever’s reliability in response to this incident and beyond.
Summary
Because (a) we hit a database concurrency threshold, (b) an internal service was particularly inefficient in its use of the database, and (c) that same internal service was not yet updated to use our best practice behavior in failure conditions, Clever logins became unresponsive once we hit a combination of increased user traffic and increased number of applications connected to districts. This happened three days in a row because that specific database threshold was previously unknown to us. Our otherwise extensive monitoring revealed no issues before the outage, and we could not immediately trace the cause of the issue once the outage began.
The specific issues we encountered are now resolved. In addition, we are putting in place a number of organizational and technical measures to ensure we stay ahead of future potential performance and reliability problems. In particular, we’ll be dedicating significantly more internal resources and working with external experts to detect any blind spots we may currently still have.
What Happened
On Tuesday morning, some failed logins were detected at 10:40am PT. Our incident response process kicked in as Clever engineers were paged and responded at 10:42am. Errors escalated quickly until all logins failed starting at 10:44am. The same set of circumstances recurred on Wednesday at 10:28am, when Clever engineers were preemptively monitoring and reacted immediately. Finally, a similar but aggravated situation recurred on Thursday at 6:29am, with Clever engineers paged and responding by 6:32am.
Though we monitor our systems extensively, none of our metrics indicated any service degradation before the outage began. During the outage, we quickly noticed:
- Two of our internal services were failing repeatedly, in particular a service named district-auth that manages the mapping of districts to applications.
- All database connections were consumed in a matter of seconds, even though the database itself wasn’t showing any other signs of distress (no CPU, memory, or I/O spike).
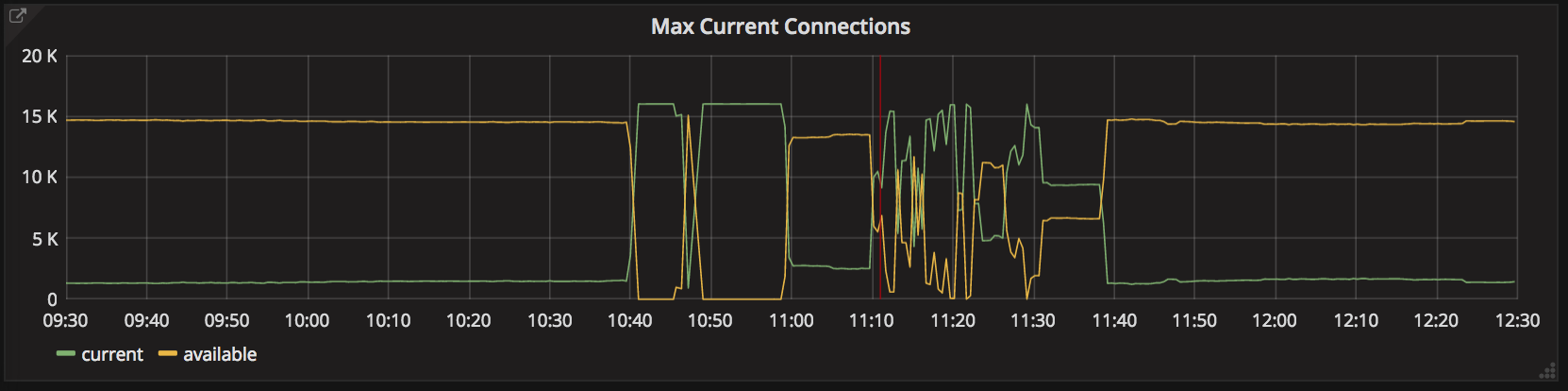
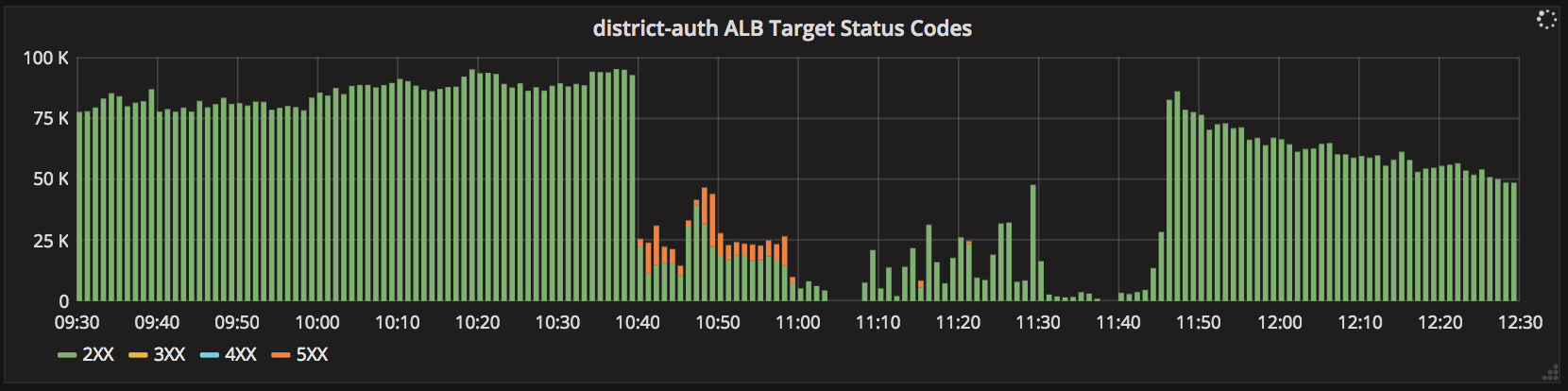
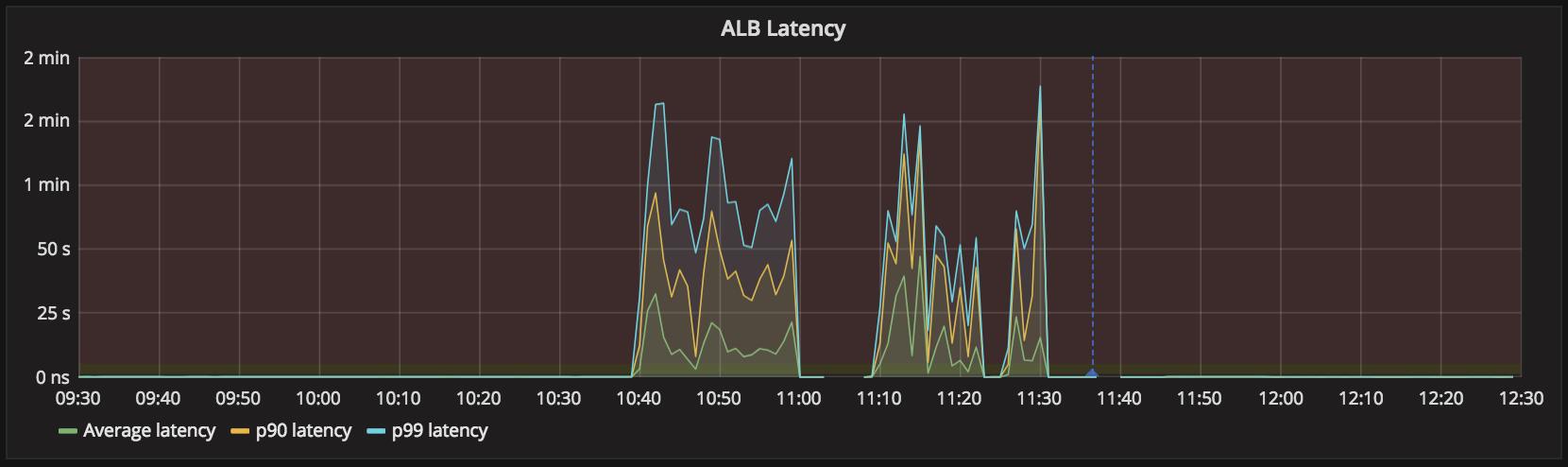
Tuesday, 10:40am: free database connections disappear instantly (top), requests served by the district-auth service collapse (middle), and latency of that service shoots up (bottom), all without any preceding degradation. Service is restored at 11:40am.
We attempted various approaches to revive district-auth, without success. Once traffic had subsided a bit on both Tuesday and Wednesday, Clever logins came back.
Attempts to Resolve & Mitigate
On Tuesday and Wednesday afternoons and evenings, after the days’ respective outages had cleared, we reviewed metrics and logs across our systems in order to determine which resource constraints we were hitting. As the issue remained unsolved late into the evening on both days, we turned to mitigation strategies.
On Tuesday, we increased CPU and memory allocation for the two misbehaving services and capped the number of total instances of those services in order to control the load on the database. After Wednesday’s outage where we quickly realized our mitigations hadn’t helped, we applied more aggressive (and thus riskier) mitigations. We designed, tested, and deployed new circuit-breaking logic in the two offending services to fail fast and prevent request build-up, and we scaled up the relevant database with significantly more powerful hardware in CPU, memory, and I/O.
Thursday Complication & Resolution
On Thursday morning, a failure in our circuit-breaking mitigation – which our previous night’s tests had failed to catch – caused the worst outage of the week. We reverted our mitigation and began a broader investigation across all Clever systems. While many explorations led nowhere, two specific ones led to our recovery.
First, we split queries from district-auth across an additional database replica, which restored many Portal logins around 10:38am. Then, around 12:10pm, we deployed a change to our login service and Portal that modified their use of the degraded district-auth service. This instantly brought Clever logins back while reducing the database load by an order of magnitude.

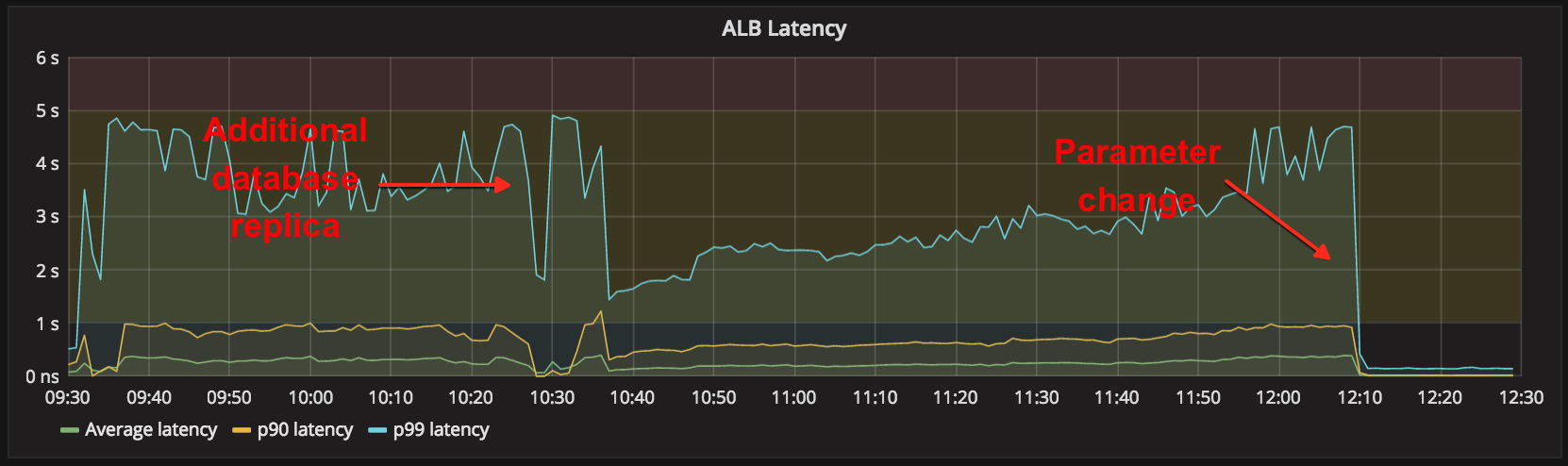
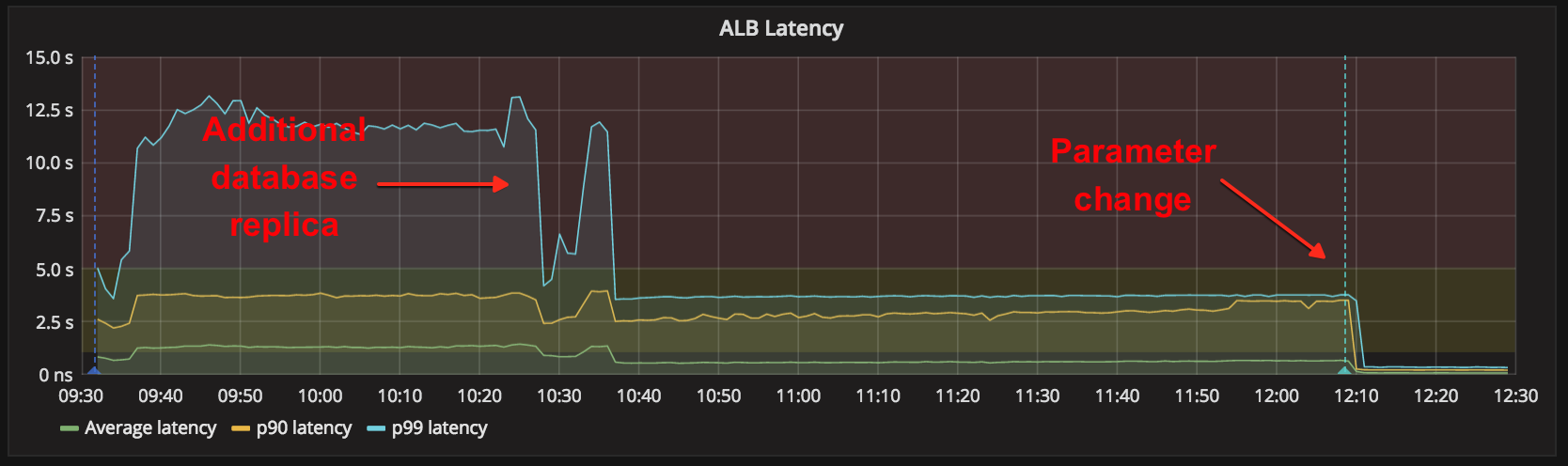
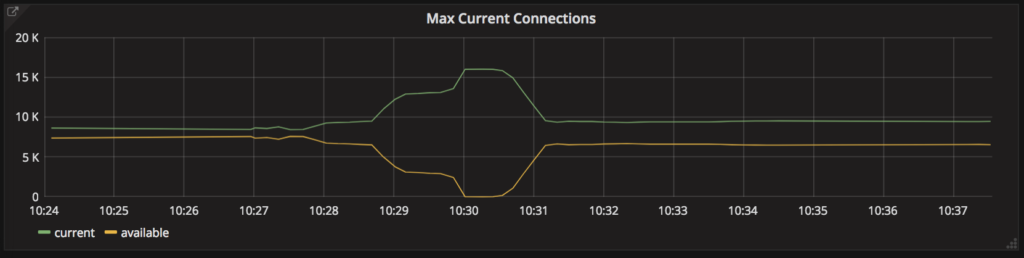
Effects of the two mitigations we deployed on Thursday.
Given the complete recovery and performance improvement, we froze all deployments and began a methodical analysis of our fix.
Gaining Confidence
On Thursday afternoon and evening, we built an improved load-testing mechanism to replay realistic peak production traffic against our internal services. We also designed, built, tested, and deployed a more aggressive circuit-breaking mechanism for district-auth. From 6pm to 9pm Pacific on Thursday, we scheduled a maintenance window to thoroughly test all of our changes against our production environment, once public traffic had subsided.
With this load testing, we were able to:
- Recreate the failure case against the prior day’s version of the service
- Validate the usefulness of our new circuit-breaker
- Validate the vastly increased capacity afforded by the change in the API call
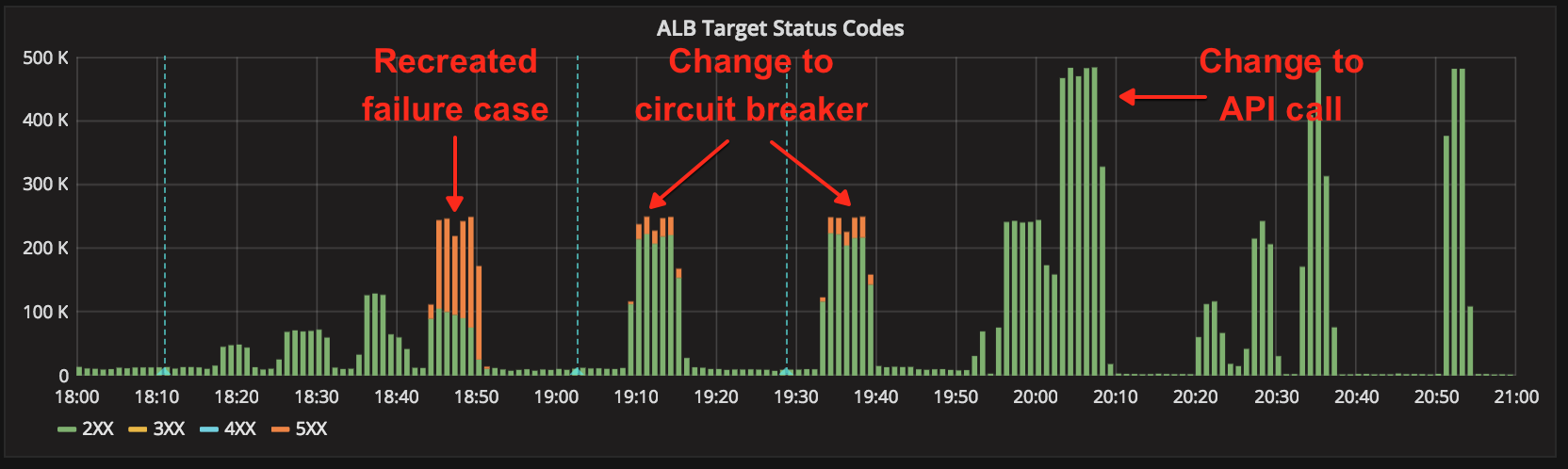
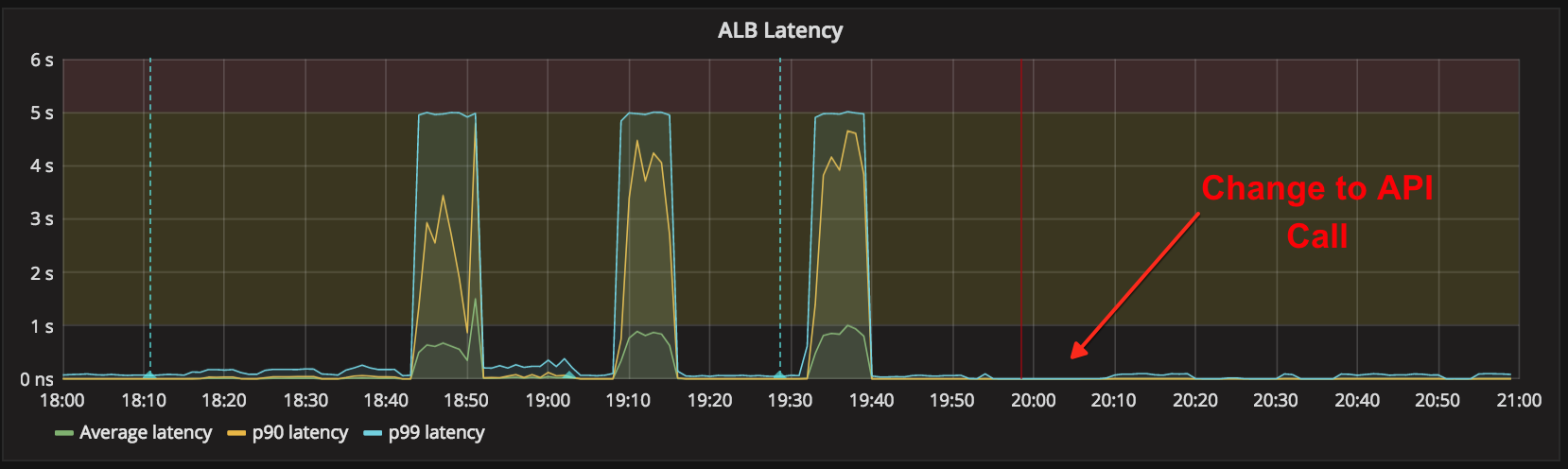
At that point, we were confident Friday would go well, and indeed it did.
Root Causes
We continued our investigation on Friday and into this week in order to fully understand the problem. We were able to determine three root causes of this outage:
- We hit a ceiling on the number of database connections that are allowed to actively read from the database at any given time – we were unaware of this threshold and had never encountered in Clever’s history.
- The district-auth service was unnecessarily making a very large number of database queries, notably on every student login.
- The district-auth service didn’t include a timeout, leaving many parallel threads continuing to make requests to the database even after the client request into district-auth had been canceled and was being retried.
As a result:
- With unprecedented traffic on Clever, we hit the read-concurrency threshold in the database (root cause #1). As a result, a number of open database connections were effectively frozen.
- Much of that database activity was coming from the district-auth service, which was making, for each request that it served, dozens of database queries (root cause #2).
- All of these database connections were in contention for the active reader slots in the database, with each district-auth request pausing before each of its database query as other connections slipped into the available reader slots.
- As a result, as soon as the read-concurrency threshold was hit, almost every district-auth request took minutes to be served.
- At the 2-minute mark, the load-balancer timed out the requests to district-auth, which meant very few requests to district-auth successfully returned before being canceled.
- Although the request was timed out, the district-auth request-serving logic proceeded (root cause #3), continuing to use up a concurrent-reader slot and performing dozens of queries – all to no end, since the client was no longer listening.
- As certain clients of the faulty service then retried their request, the number of simultaneous requests into district-auth ballooned rapidly. With requests piling up because of organically increasing traffic plus the retries, district-auth kept opening up new connections to the database, thus exacerbating the problem of contention for reader slots, and the service couldn’t recover.
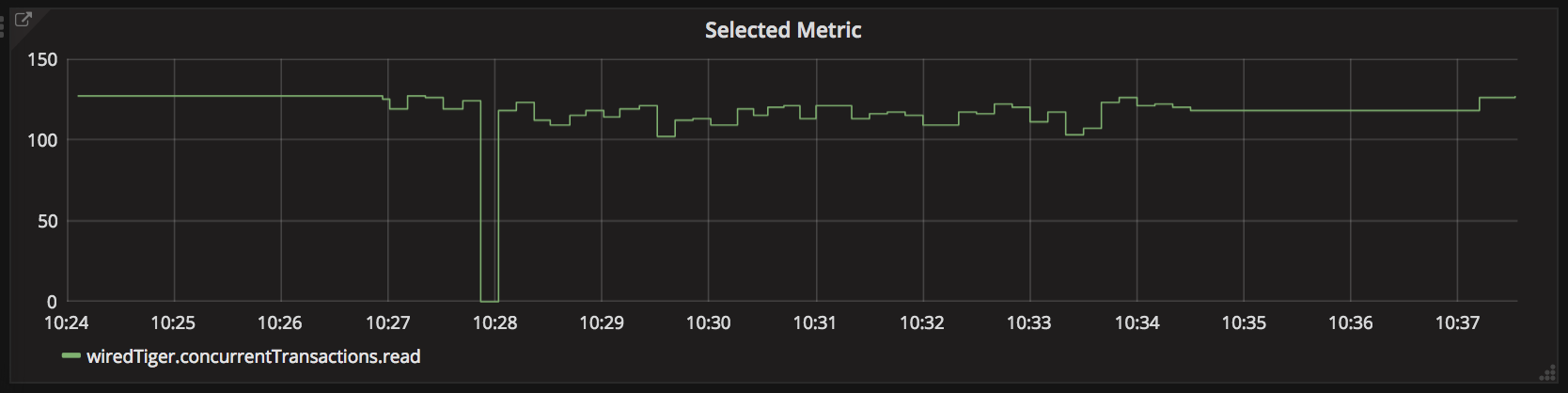
Once we’d identified the read-concurrency threshold, we were able to retroactively see it trigger rapid performance degradation: at 10:28am, the concurrent readers are maxed out, leading to district-auth rapidly using up database connections.
In the end, the three root causes combined to make district-auth immediately unusable given the combination of increased traffic and increased number of applications per district. Every time we attempted to restart the service, the read-concurrency threshold was hit almost instantly, and district-auth became unusable again for almost every request it received.
An Analogy: Checkout Lanes at the Grocery Store.
It may help to use an analogy to understand the resource contention we experienced: imagine a busy grocery store. There are only so many checkout lanes, and there are enough customers that all the checkout lanes are busy. If every customer pays for all of their items all at once, as you would expect, then shopping may be a bit slower as the number of customers increases, but customers are still making it out of the grocery store at a steady clip.
Now consider, instead, an odd grocery store where each customer needs to stand in line and pay separately for each item they’re buying. Stand in line for butter, pay for it, return to the end of the line, and wait for another turn to pay for the eggs, and so on. Technically, the grocery store is processing just as many purchases as before, but a single customer will take much longer to make it through, and will probably give up before they’ve finished their shopping.
To make such a grocery store more effective at getting customers out the door, there are two approaches: bundling items together so the individual number of purchases goes down (i.e. crafting better database queries that bundle results together), and making sure that no unnecessary items are purchased (i.e. removing unnecessary database queries). Those are two of the mitigations we’ll be implementing to address this specific problem.
Actions We’re Taking
For the specific issue we encountered, we have already deployed the key fix of dramatically reducing the number of database queries we make, giving us headroom to grow our database usage by an order of magnitude. We will be continuing these specific mitigations by also crafting better database queries for this specific endpoint, so that the same need can be met with far fewer queries.
More importantly, we’re making important changes to how we think about and tackle performance and robustness. While we’ve long had monitoring and incident response processes, we need to do more to stay far ahead of performance issues we can measure today and to detect performance issues we don’t yet know about.
To that end, we’re taking the following actions:
- All critical internal services will be automatically rated on service health with particularly stringent parameters for response time and database usage. Any degradation in service health will create on-call tickets for engineers to address immediately – something we already do for a number of other metrics.
- Load testing will be expanded to all critical internal services, with regular load testing substantially exceeding expected traffic in a realistic production setting, giving us the ability to detect new performance issues long before they might affect the classroom.
- We’ll dedicate a full-time engineering team to the task of methodically investigating potential performance and reliability problems, upgrading the service-health report cards, continually improving our automated load testing toolchain, and striving to discover new classes of potential problems. This allocation is in addition to our existing Infrastructure team that manages all deployments, logging, and alerting.
- We will be engaging external database experts to review all of our operational practices, including every configuration parameter we monitor and alert on. We want to make sure we’re not surprised by any other resource constraint.
We’ll be reporting on our progress regularly on this blog, including the actions we’re taking, the effect they’re having on internal metrics, and our measured uptime on a monthly basis.