When building systems for new products, there’s a delicate balance between writing code that works and writing code that lasts. A common anti-pattern is preemptively optimizing systems for the future while still trying to find product market fit. For new product teams, this can be a costly mistake as it leads to a slower iterative cycles between product experiments.
At Clever, the Discovery team is responsible for facilitating the discovery and usage of ed-tech applications in the K-12 space. As one of the newer product teams, we were tasked with quickly iterating on different experiments to find a product that would fulfill this mission. This resulted in the Clever Library, a marketplace for ed-tech applications where teachers can discover and use new applications with their students. Applications in the Library automatically provision user accounts based on information teachers allow them to access, leading to a seamless experience.
When we built the Library in Spring of 2018, we designed it so that we could get up and running as quickly as possible while still being reasonably flexible to change. But as more and more teachers became active users of our product, we realized we needed to reinvest in our original system to handle our new usage projections.
In this blog post, we’ll talk about how we evolved from an experiment with 50k monthly active users to a scaled version that now supports over 800k monthly active users.
Building something that works
The core responsibility of the Library backend is to answer the question “what school information is shared with this application?” If a teacher installs an application, we want to share the pertinent school information with the application so that they can create the relevant user accounts.
To answer this question, we track student information system (SIS) data and sharing rules that represent connections between users and applications. By applying sharing rules to SIS data, we can figure out what information should be shared.

We had an existing Mongo database that stored SIS data and we introduced a new Dynamo table that stored sharing rules.
- write-service managed the rules in DynamoDB.
- read-service fetched information from DynamoDB and sis-service (the API for our SIS MongoDB). It then used sharing rules and SIS data to compute the information that should be returned to the application.
We made the following decisions to minimize the amount of work to ship our backend.
Reusing existing systems
We reused existing systems and tooling to expedite development. It was easy to use existing databases and services for SIS data, and Clever had tooling that made spinning up and using DynamoDB dead simple. Engineers also had experience with these, so there was a clear path forward when we started implementing our designs.
Evaluating business logic on read
We performed the bulk of our business logic at read time to figure out what SIS data was shared with an application, given existing sharing rules. Evaluating business logic at read allowed our data model to be simpler and enabled us to make small product changes more quickly.
Scaling challenges
Despite being easy to build, simple, and quick to iterate on, the original system we designed started suffering at increased load. At Clever, we perform nightly load tests to catch any issues with running our services at scale.

We send requests to recreate this gradual ramp up in requests like you see above, until we hit our steady state peak load.
The following is a snapshot of our application load balancer latency for read-service during one of these load tests. This snapshot is taken at a steady state peak of ~36 queries per second (qps).

In the highlighted sample above, we can see the distribution of read-service latency in a worst-case event. The 99th percentile of long running requests (P99) exceeds 4 seconds, but you can also tell that outside of this outlier, our latencies across the board are still high. When load approached 50qps, our P50 latency began to exceed 200ms, which is when our load balancer timeouts killed the requests. We had the following pain points:
Our system was not performant at scale
- Response times scaled with the number of classes a teacher taught, so we set a class limit of 20 so that teachers with more than 20 classes could not install applications. Even then, our P99 was very bad (over 500ms at 50qps).
- Poor response times (P50 greater than 100ms) meant slow load times for Library applications, regularly failing at our timeout threshold of 200ms.
Our system was complex to develop in
- Business logic was complex since we had to reconcile sharing rules with SIS data for every endpoint in read-service.
- Although it was easy to make simple changes to our backend, it was very difficult to make major product changes to support more sophisticated types of sharing.
- Querying DynamoDB is more restrictive than SQL. This didn’t work well for our quickly changing product since we often had to add new global secondary indexes and perform backfills to support new query patterns.
Goals
As we prepared for the 2019/2020 school season, we realized that we needed to support significantly more traffic and to do so under tighter latency SLAs. We also envisioned a plethora of extensions so that teachers could share Library applications with finer granularity and control. This led to the following goals:
- At a minimum our new service should be able to support a peak of 500qps while maintaining a P99 response latency of less than 250ms.
- Our database should ideally be able to scale automatically to handle increases in traffic.
- It should reduce the complexity of our existing system in order to enable our engineers to develop on our backend and quickly support new feature requests.
Building something that lasts
Our new scaled system is powered by a Serverless Aurora MySQL database that consolidates both the SIS and sharing data that we need. We chose Serverless Aurora because it provides high availability and fault tolerance. But most importantly, it vertically scales automatically with changes in traffic.

Evaluating reads
With both sharing rules and SIS data in MySQL, we can use SQL joins to relate both pieces of information. For example, to find out if a teacher is scoped to an application, we might use this high level query:
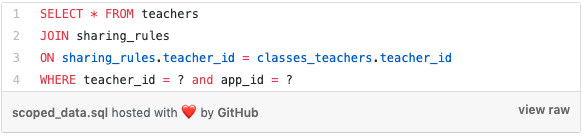
We could apply this same basic concept to every other read path in read-service. What once required pulling data from two data stores and joining across the data in code can now be done in a single optimized SQL query.
Challenges
There were several challenges we faced that made it significantly harder to start with this scaled system. Both of these added extra work that we couldn’t justify when building our initial system.
Modifying our critical ETL pipeline
At Clever, we have a critical ETL pipeline that keeps SIS data updated in our SIS Mongo database. Specifically, we had a step in this pipeline, load-sis, that ingested events and wrote to a Mongo database. This SIS data is then used in downstream processes to power Clever’s auto-rostering. To consolidate SIS data and sharing data in a new database, we needed to make changes to this critical pipeline which was both complex and high risk.
For our scaled system, we added a step in our ETL pipeline, load-mysql-sis, that ingests events and performs updates to our MySQL database. With this in place, our write-service began a dual write pattern to both our MySQL database and our Dynamo database until we were ready to fully migrate over.
Using SQL
There was also friction with even using a relational database. At the time, Clever lacked tooling to manage and spin up new relational databases. There was also a gap in domain expertise – we didn’t know how to use SQL safely and effectively. These gaps added ambiguity in our estimates as well, as it was hard to forecast the issues that might arise if we chose to use SQL.
Result
This is a snapshot of read-service latencies during a load test on our scaled system. Here we’re at a steady state peak of 500qps:

Previously at 50qps, we averaged a P50 of 200ms and a P99 of 500ms. Now even scaled at 10x the load, our P99 averages 40ms (90% decrease) and our P50 latency averages 25ms (87% decrease). Because our latency was also no longer tied to the number of classes a teacher taught, we also could now remove the 20 class cap that we previously enforced on teacher installations.
Takeaways
Reduced system complexity
Going from a read service that orchestrated calls to various databases, performed in code joins to reconcile across different data types, to a single SQL query against a single database vastly reduced the complexity of our read service. It has also made it easier to identify and triage issues since we had fewer dependencies.
Vertical scaling and relational data
With Serverless Aurora, we can vertically scale our database cluster as our request volume grows. In our old system, performance was also tied to the number of classes a teacher taught. So our worst case was always teachers who taught many classes. By leveraging the SQL engine on very relational data, our scaled system still performs well for these teachers.
Unknown unknowns with new technology
This project was the first production usage of Serverless Aurora at Clever, which was also a newer AWS offering at the time. We chose it because it offered many of the qualities we wanted in a datastore, but this also meant that there were many unknowns when it comes to actually using it. Our key learnings are:
- Pausing should be turned off in production. Startup typically takes ~30 seconds which is an unacceptable amount of time for a production system to warm up.
- Slow query logs are not enabled by default so you should create a custom db parameter group to enable them.
- Fine tuning connection pools is hard especially with containerized services. You need to fine tune how you manage your connection pool and how you handle retries to deal with Aurora scaling events. Matching your connection pool properties with how your service scales with CPU and memory can be very tedious.
Looking ahead
Our new scaled system has been humming along for the 2019/2020 back to school season. But there are always improvements to be made to ensure reliability and ease of future development. In the next few months, we’re looking to make more changes to our data model to enable more sophisticated types of sharing. We’re also investing in more SQL tooling so that it’s easier for engineers to use Serverless Aurora and SQL generally in new projects.
If you enjoyed reading this and would like to work on similar types of challenges, our engineering team is hiring!