Two months ago, we experienced the worst outage in the history of Clever SSO. We wrote up a postmortem soon afterwards. We mentioned at the time that this postmortem was the beginning of our process to reevaluate everything we do to make sure we can be worthy of the trust you place in us. We want to update you on where we are now.
At a high level, we have fully addressed all issues that contributed to the specific March outage. We are now working to ensure that, by Back-to-School 2018, we have the architecture and processes in place to prevent all reasonably foreseeable failures. This includes changes in behavior under load and as code evolves, as well as significantly improved means to respond to a number of unforeseeable failures, including hardware and networking failures. Finally, we are embarking on an 18-month project to build the highest level of resiliency for Back-to-School 2019, where we will be resilient to all classes of hardware and network failures, including an outage of an entire Amazon Web Services region, by building redundant stacks in geo-distributed locations.
People
At Clever, we believe people are the foundation of everything we do. In response to the outage, our first move was to grow our infrastructure team by 40% and revamp its mission to focus on resiliency. That immediate shift has allowed us to make significant progress already. In addition, we worked with consultants and advisors AKF Partners and Bill Coughran to review our architecture. We’re now executing on a new roadmap to address their recommendations.
Metrics
We’ve settled on a metric for measuring our uptime on a monthly basis, and we’re keeping it simple:
- A minute is counted as “down” if more than 10% of attempted logins in that minute fail to complete. It is counted as “up” otherwise.
- Our monthly uptime is the fraction of “up” minutes out of the month.
- We will occasionally have maintenance windows that we won’t count, and of course we’re committing to keeping those maintenance windows outside of school hours in all US timezones.
- We’re aiming for 99.95% uptime, which is no more than 20 minutes of downtime per month. We expect to hit 99.9% for the first few months as we deploy a number of measures to rapidly respond to downtime, and we are aiming to hit 99.95% regularly in a few months.
Using this metric, Clever’s uptime in 2018 so far has been:
- 99.915% in January
- 100% in February
- 99.355% in March (during our major outage)
- 100% in April
More on the Root Causes
We had a reasonable understanding of the incident in the few days that followed. Specifically:
- We hit a ceiling on the number of database connections that are allowed to actively read from the database at any given time — we were unaware of this threshold and had never encountered it in Clever’s history.
- A service was unnecessarily making a very large number of database queries, notably on every student login.
- That service didn’t include a timeout, leaving many parallel threads continuing to make requests to the database even after the client request into that service had been canceled and was being retried.
Since then, we’ve discovered more details that paint a complete picture of what happened:
- We now understand the trigger event: there is a bug in the version of the datastore we’re using that causes significant lock contention on some internal data structures that appears specifically when running the particular kind of query that the service was making unnecessarily and quite often. This bug, once triggered, also dramatically reduces the performance of our datastore until all connections to it are released. We were able to recreate these conditions in isolated test conditions. This explains how we hit the read-concurrency limit.
- We now understand the failure cascade: the host instance health check in the culprit service caused the service to go unhealthy the moment we ran out of DB connections, thus exacerbating the problem significantly as other instances of the service were further overwhelmed, triggering a cascade.
- We now understand why this issue occurred in March and not in November (a roughly equivalent peak-traffic period): in January, we changed the configuration of some large districts that resulted in a significant increase in the number of sharing rules between those districts and applications. This was an expected outcome, and there’s nothing wrong with the outcome. However, because the unnecessary and particularly inefficient behavior in our sharing service specifically depends on the number of sharing rules, this change pushed the service’s behavior beyond the threshold that triggered the datastore bug.
Since the outage, we have:
- removed the inefficient behavior in the culprit service
- added proper timeouts and resource cleanup
- fixed the health-check in the culprit service and others
- significantly reduced the use of the bug-triggering queries to a level which we are confident will no longer elicit the lock contention
We are also planning a database upgrade in the next few weeks. We aren’t rushing this upgrade because (a) there is a good bit less time pressure now that we have bought ourselves an order of magnitude of headroom in our services’ performance with the improvements above, and (b) we prefer to be particularly cautious with database upgrades as a general rule, since they can cause more problems than they solve. We will be working on a plan for this upgrade over the summer.
The Plan for Back-to-School 2018
For Back-to-school 2018, we are focusing on two major initiatives: comprehensive load testing and strict service isolation.
Comprehensive Load Testing
For comprehensive load testing, we have built tools to perform two types of testing:
- Replaying read-only production traffic at night on individual internal services. The goal here is to understand if any changes made in a given day of Clever engineering has caused a noticeable change in the performance profile of our systems. We are using recent production traffic patterns, replayed at 120%, to load test our key internal services on a nightly basis. Regressions in performance, even if they don’t rise to the level of an outage, are investigated as early warning signs.
- Synthetic traffic generation of logins to Clever, including the Portal and a sample application. The goal here is to understand where our systems’ breaking points are, and to continually upgrade our architecture to anticipate Clever’s growth by many months.
The replay testing work so far has already helped us prioritize optimization of two key services that, while they function acceptably well, could be a good bit better. This testing also identified a rare memory leak in one of our services, which we’ve addressed.
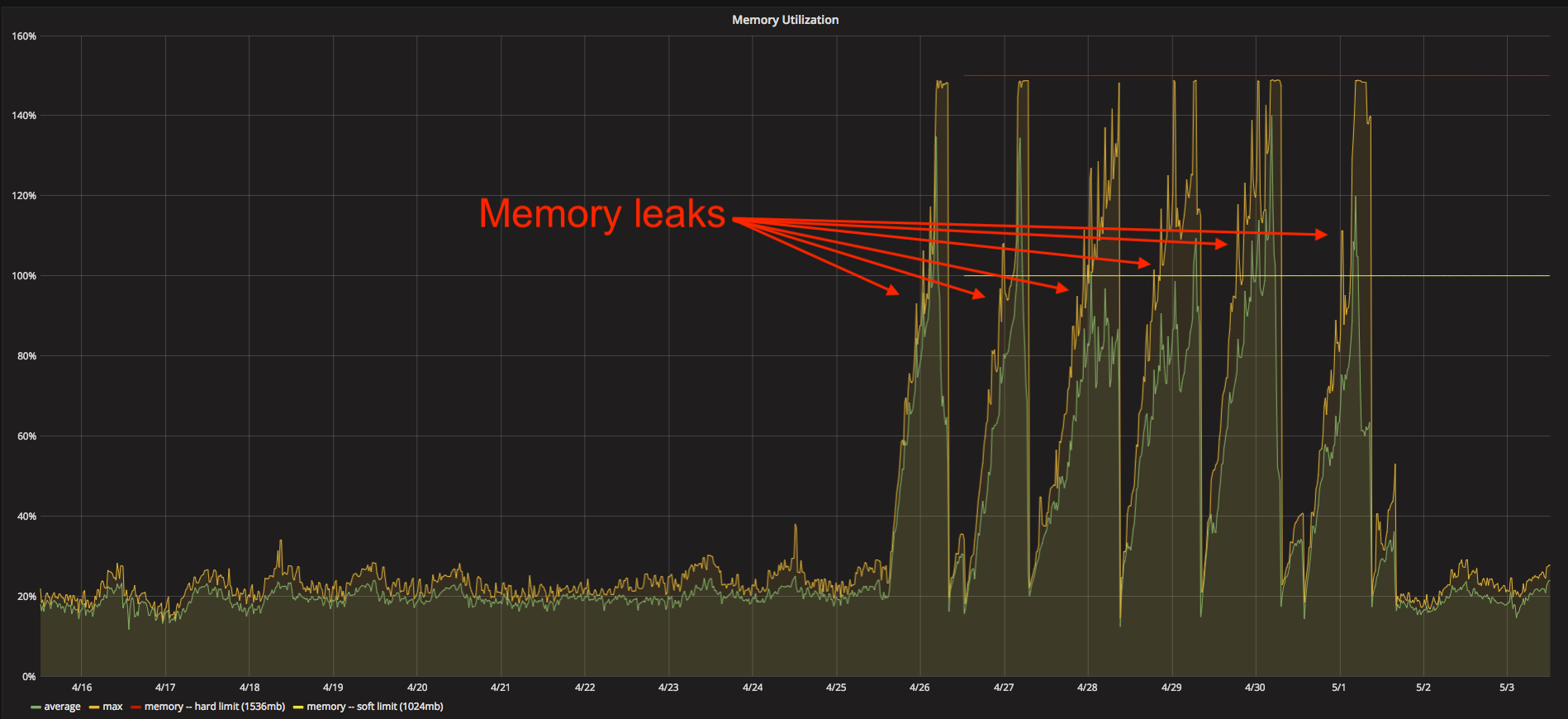
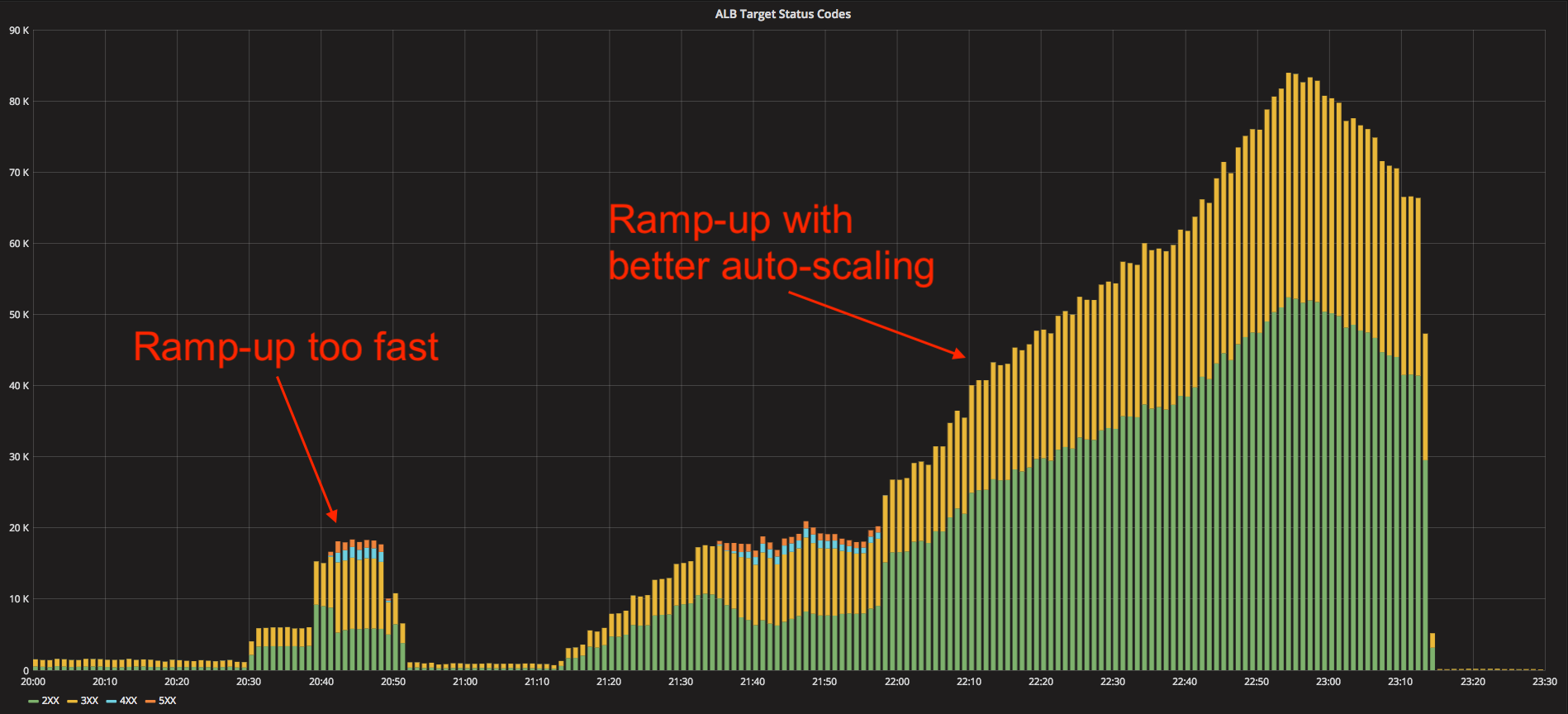
The synthetic traffic generation – which we’re still actively working on – has already revealed that our autoscaling process was likely a bit too slow for the anticipated September traffic. Had we not detected this, we might have had transient errors in the Fall. Now that we have, we have made our auto-scaling process more sensitive.
Strict Service Isolation
We are in the process of reviewing all of our key services – the ones necessary for SSO to function. Every service dependency is being reviewed – we anticipate being able to remove quite a few as we garbage-collect older code and assumptions. Once we’ve pruned this dependency tree, we’ll be creating isolated copies of these services for the SSO flow only, as well as creating new database replicas dedicated to the SSO flow. This means that any heightened sharing activity or use of the administrative dashboards should be mostly isolated from the critical SSO flow. We’re also defining Service Level Objectives (SLOs) for these critical services that will alert us when performance falls outside of a specified acceptable range. As this work has just begun, we’ll be updating you on its progress in a few weeks.
The Plan for Back-to-School 2019
We’re beginning to map out what it will take to run fully independent Clever stacks in multiple AWS regions. We’ll be making architectural changes over the next few months, all invisible to users, to prepare for this, and we expect to be testing in Spring 2019. We’ll keep you posted on this blog.
Communication Plan Update
Finally, a key part of our plan for Clever resiliency is improved communication with our customers in the unfortunate event of downtime. We have already improved our Statuspage configuration (https://status.clever.com) to delineate different types of outages, and we’ve created a Twitter account to provide an additional communication channel on potential issues affecting logins: https://twitter.com/ssostatus.
We’re also actively working on providing in-product notification of outages, so that users attempting to log in will, in most cases, be presented with a notification of the outage and information about what to do next. We’ll have more news on this topic in a few weeks, once we’ve implemented it.
Clever is your Critical SSO Infrastructure for Education
We know that we created a lot of pain and delays and frustration for many teachers and students around the country in early March. One of the key principles we are holding ourselves to, in the aftermath of that outage, is that we will be honest and transparent about our work and the significant improvements we’re planning. No system can ever be perfect, but we know we can do more than what we did earlier this year, and we hope these updates will help you see the significant steps we’re taking to make sure you can rely on Clever.