Everyone in the US is now back in school, and we’ve been feeling the rush of excitement here at Clever over the last few weeks. On a typical day at Clever this school year, we regularly hit more than 1,000 logins per second!
As we’ve chronicled over the last few months (July, May) , the Clever engineering team has been working to make sure that Clever is particularly resilient during this Back To School. We’re pleased to report some great results:
- In July, our uptime was 99.93% (this was ok but not great)
- In August, our uptime was 99.997%
- In September, our uptime was 100%
In this update, we want to tell you about the work we’ve done to make this Back To School so successful. We also want to cover the mistake we made in July that caused 25 minutes of downtime, even if that downtime affected very few students, and what we learned from it. We’ll tell you about the networking failure in September that our systems handled with grace, and we want to tell you about the next steps we’re taking to make Clever even more resilient in the future.
July Outage
In mid July, we deployed subtly faulty code in our authentication service. This caused logins to applications to fail, while logins to the Clever Portal itself were successful. Students could get to their Portal screen and would then encounter an error when clicking on an application. We didn’t notice this issue for 25 minutes, at which point we reverted the change and immediately resolved the problem.
In our retrospective, we noticed two flaws in our testing that caused us to miss this issue: (1) our automated testing included a login to the Portal, but not to a learning application, and (2) we were not issuing 500 error codes in this particular error case because of how we had interpreted the OAuth specification. These two issues put together prevented us from automatically detecting this problem quickly: an automated test failure, or a rise in 500s would have automatically paged us. We have since fixed both of those issues, and we’ve added more safeguards to our deploys that compare error rates between old and new code:
One bit of consolation: this outage lasted 25 minutes only because Clever’s login activity is generally low in the middle of the summer. At any other time, we are confident that we would have remedied this issue in under 5 minutes. That’s still not good enough, of course, which is why we invested in preventing this kind of problem with our new deployment guardrails.
Load-Testing-Driven Improvements
Over June and July, we conducted a number of stress tests to better understand the limits of our system. We covered these in a previous blog post. Then, in late July and early August, we deployed a nightly load test for the purpose of detecting subtle issues at higher loads in an automated way, and for the purpose of detecting performance regressions over time. These load tests are higher than a typical day, but not so high as to cause disruptions the way stress tests sometimes do. This is what these nightly load tests look like, compared to our daily load over the last few days:

Load testing vs. daily load: the high peaks show nightly load testing, the smaller bumps are normal daily traffic.
On a one-day scale, you can see the requests serviced by our launchpad service, first during the normal hours of the school day, then with the synthetic load test starting around 7pm and culminating at approximately 2x normal load:
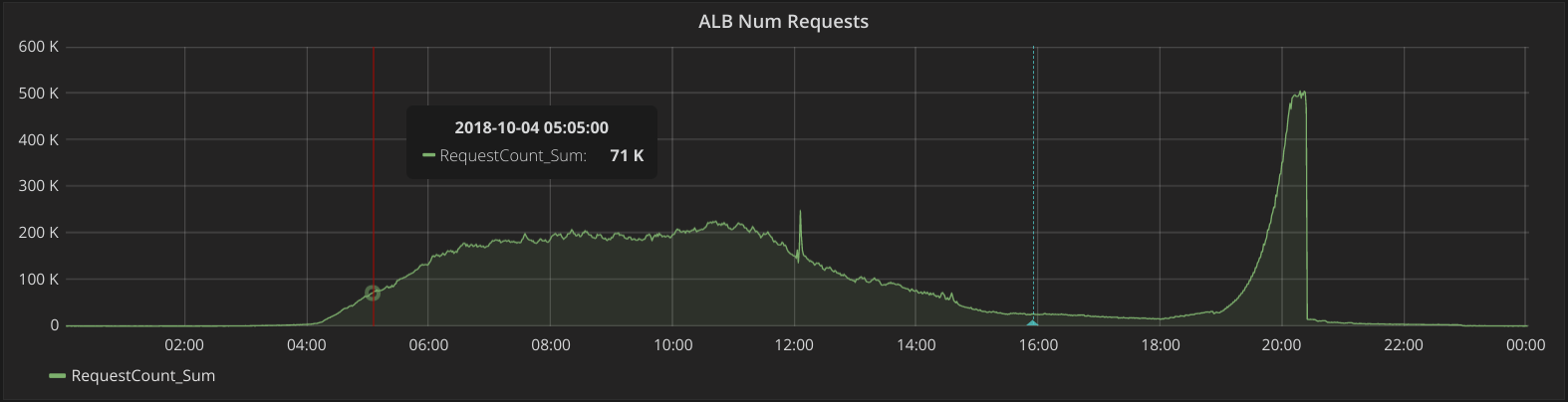
With this load test every evening, we are confident that, in cases where we deploy new code that happens to perform less well, we will discover this quickly and be able to revert those changes before they affect students the next day.
The load tests have also been invaluable in detecting subtle issues at high scale. From perusing error logs that we now generate nightly, we’ve been able to safely move to HTTP keep-alive between our internal services, which has substantially improved performance, all the while catching and resolving subtle issues, like increasing the Node.js threadpool for DNS lookups, and adding retries for Amazon DynamoDB. More and more, these load tests are helping us catch subtle quality and performance issues in production, before they affect our users.
Successful System Response during September Minor Outage
In mid-September, we experienced a new type of failure with our hosting provider. At 4:30am Pacific, just as traffic for the day was ramping up (the East Coast uses Clever a lot!), a critical load balancer — which is technically backed by redundant hardware — suddenly became unable to reach a majority of its backend service instances. Because the service in question is critical to logins, this means that errors started to occur for students logging in.
What happened in the next 90 seconds is particularly interesting. First, our automatic retries kicked into action and, because the network connectivity wasn’t broken to all backends, succeeded every now and then. This meant that a majority of the login attempts succeeded through sufficient internal retries, even during this very significant network outage. Of course, those retries caused a significant increase in load on the service in question, which was compounded by the rise in traffic at that time of day. That’s when our circuit-breaking mechanism kicked in, preventing too many retries from overwhelming the service. We ended up with some low rate of inevitable errors, without overwhelming the service with retry load. Once the networking issue was resolved, which happened in 90 seconds, everything returned to normal. By the time our oncall engineer got to his computer, the problem was automatically resolved.
The particularly important lesson here is that the work we put in to make Clever more resilient has proven to be particularly useful: first, retries allowed a great number of users to get through, even under very high low-level-service error loads. Then, our circuit breaking prevented the service from being overwhelmed, and enabled our systems to recover almost instantly once the networking issue was resolved. In the end, because fewer than 10% of users were affected, this significant network outage wasn’t even perceived as downtime by most students and teachers, and allowed more than 90% of users to log in successfully. Thus, we maintained 100% uptime in September.
Up Next: Even Safer Deploys & Multi-Region
We’re proud of what we’ve accomplished for teachers and students this Back To School. Still, we know we’re not done. Resiliency is a never-ending effort, especially as our product is growing by leaps and bounds and students around the country are relying on Clever more and more. Over the next few months, we’re going to be working on two significant engineering efforts: safer deploys, and multi-region service.
With safer deploys, we’re going to be ensuring that new versions of code we deploy will be visible to automated end-to-end tests in production before most of our users interact with this new code. This may sound obvious, but it’s far from trivial: we know that modern systems cannot be properly tested in test environments, that proper testing of all complex system interactions happens only in production. That is why we have canary deploys, which allows new code to be introduced to only a fraction of requests in production, and why we watch the error rates on those canaries before deploying to all server instances. With safer deploys, we’re doing even more: we’re forcing traffic from our end-to-end tests to work against canaried services at all times. This way, new code is released to a small fraction of users but to all end-to-end tests, and complex errors will be detected in production before most users interact with that code. We expect this to yield a significant layer of safety for all code deploys.
Most importantly, we know that sometimes, hosting providers fail. We saw it in September with a small network outage as described above. What would we have done if the network outage had lasted many minutes? The only solution to this is to move into the holy grail of software services: fully independent and redundant stacks in geographically distributed regions. We’ve begun prototyping this, and we’ll be continuing to work on these prototypes throughout 2018. In early 2019, we’ll begin production implementation, so that by Back To School 2019, we’ll be able to take action when a significant problem occurs with our hosting provider, simply by redirecting traffic to another region. With that in place, we’ll be able to shoot for 99.99% uptime, or less than 3 minutes of outages per month, reliably. This will put Clever in the top tier of online services available today. We’re proud of that, and proud to be doing everything we can to make sure that students and teachers across the country can always count on Clever.